The buzzword at the moment is Big Data where you have to make sense of lots of observations, but the problem we’ll discuss here is Wide Data where you have lots of observables. Another way of describing this is having too many dimensions. The question we will try to address is whether we can reduce the number of dimensions while retaining as much information as possible. That’s the goal of Principal Component Analysis (PCA).
PCA is fundamentally a rotation of the data onto a new set of axes. The rotation is chosen such that the projection of the data onto the first axis has the largest possible variance. That way when you specify the coordinate of each data point on that axis it separates the data as much as possible squeezing the maximum amount of information onto that first axis. The second axis is chosen such that it is orthogonal to the first axis but captures the maximum amount of residual variance as possible, and so on. PCA is most effective if by the time you get to the third, fourth etc. axes there is hardly any information left to describe.
The example we will use is the US yield curve. The yield curve measures interest rates at which the US Government can borrow over different periods of time (maturity) usually up to 30 years. This means we have a rate for each maturity of loan for each day in the past. Here we use 6 maturities and so we have a six-dimensional yield curve.
Mathematically we set up the problem starting with some data in a matrix
The diagonal elements of \(D\) are the eigenvalues. The columns of the rotation matrix \(R\) are the eigenvectors. The function in R for performing principal component analysis is prcomp() and it returns the eigenvalues and eigenvectors as follows:
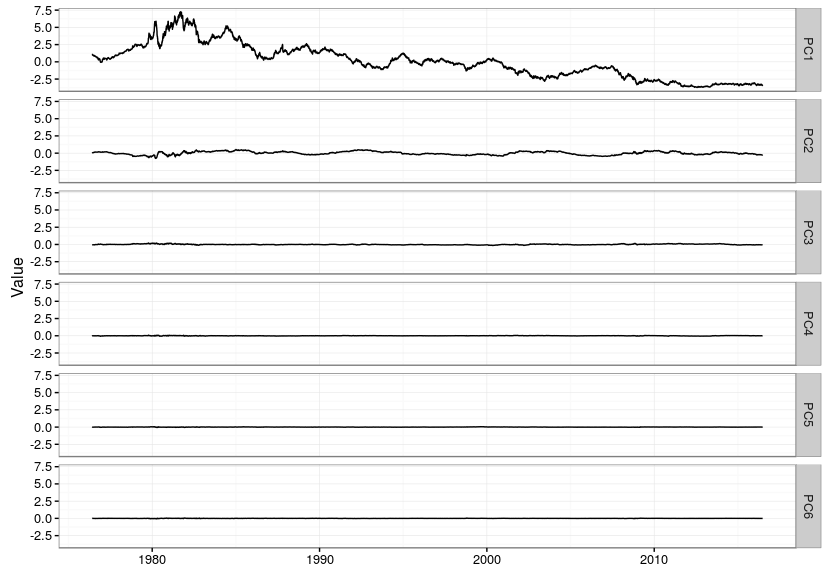
This shows how to download the yield curve history (and cache it), calculate principal components and then plot the components over time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
library(quantmod) library(zoo) update_fred <- function(start="1950-01-01",cacheFile="/home/ramin/FREDTreasury.RData") { library(quantmod) identifiers <- c("DGS1","DGS2","DGS3","DGS5","DGS7","DGS10","GS20","DGS30") fred <- as.zoo(getSymbols(identifiers[1],src='FRED', auto.assign=FALSE)) for (i in 2:length(identifiers)) { fred <- merge(fred,as.zoo(getSymbols(identifiers[i],src='FRED', auto.assign=FALSE))) } save(fred,file=cacheFile) } get_fred <- function(cacheFile="/home/ramin/FREDTreasury.RData") { load(file=cacheFile) return(fred) } # uncomment and run this once to get the latest data and update the cache #update_fred(cacheFile="/home/ramin/FREDTreasury.RData") # get yield curve history y <- get_fred() # 20y and 30y have gaps so miss them out y <- y[,c("DGS1","DGS2","DGS3","DGS5","DGS7","DGS10")] # remove any day with missing data so series have no NA values y <- y[!is.na(apply(y,1,sum)),] # rename columns colnames(y) <- c("1y","2y","3y","5y","7y","10y") # calculate principal components y.pca <- prcomp(y,scale = TRUE,center = TRUE) # first principal component sign flip so it's an upward shift in yield y.pca$x[,1] <- -y.pca$x[,1] # also have to flip sign for eigenvector y.pca$rotation[,1] <- -y.pca$rotation[,1] # how much variance is captured in first n eigenvectors? cumsum(y.pca$sdev^2)/sum(y.pca$sdev^2) # plot eigenvectors library(ggplot2) ggplot(data.frame(cbind(term=c(1,2,3,5,7,10),y.pca$rotation[,1:3]))) + geom_line(aes(x=term,y=PC1),colour="red") + geom_point(aes(x=term,y=PC1)) + geom_line(aes(x=term,y=PC2),colour="green") + geom_point(aes(x=term,y=PC2)) + geom_line(aes(x=term,y=PC3),colour="blue") + geom_point(aes(x=term,y=PC3)) + theme_bw() |
This is what the eigenvectors look like. The red flat line is the first principal component, and corresponds to a parallel move up and down in the level of the entire yield curve. The green line is the second principal component and is a steepening and flattening of the curve. The third component is a twist. In the code above you will see he comment about how much variance is captured in the first few principal components. For this data the first principal component captures a staggering 98.98%! The second component manages to capture 0.96% and the third component 0.05%, beyond that only 0.01% of variance remains.
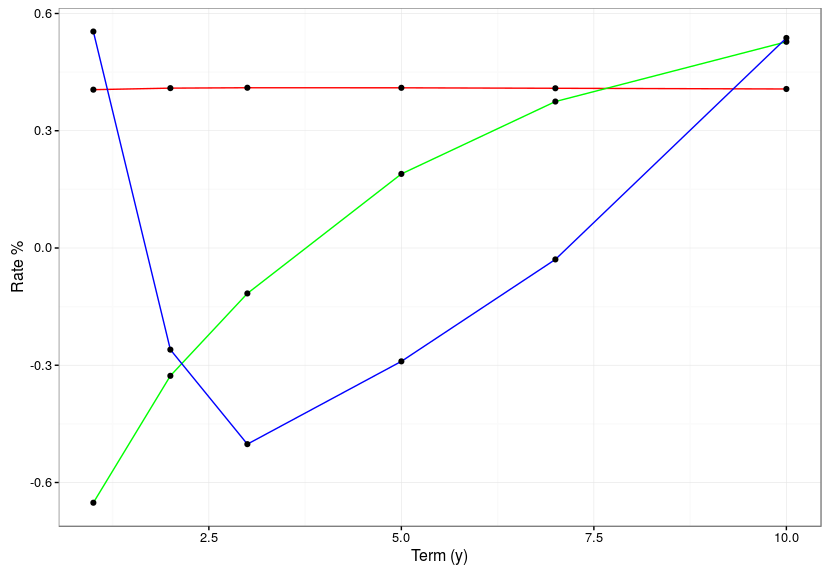
The reason why PCA is so effective for yield curves is that rates are highly correlated. Yield curve levels in the US are at least 96% correlated and daily rate moves are at least 72% correlated. Looking at the “loadings” of the yield curves onto the eigenvectors we see that the volatility after the second principal component is almost zero because all the information about yields is squeezed into the first two principal components.
|
1 2 3 4 5 6 7 8 9 10 |
# correlation is extremely high across the term structure round(cor(y),3) min(cor(y)) # lowest is 96.0% in yield levels min(cor(diff(y))) # lowest is 72.0% in daily yield changes # plot yields rotated and projected onto new principal component axes ggplot(fortify(zoo(y.pca$x,as.Date(rownames(y.pca$x))),melt=TRUE)) + geom_line(aes(x=Index,y=Value)) + facet_grid(Series ~ .) + theme_bw() + theme(axis.title.x=element_blank()) |
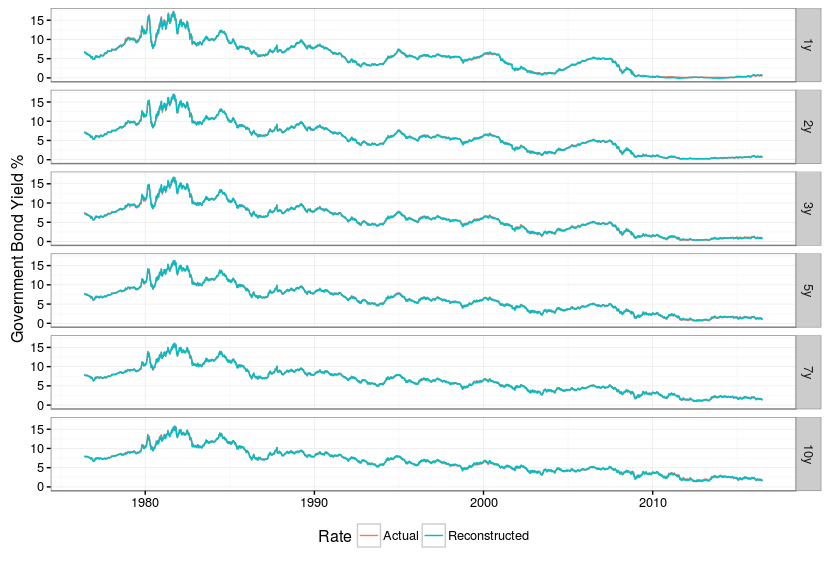
If we take the information from the first two principal components and reconstruct the entire yield curve we can assess how much information we have lost by throwing away four dimensions. The answer in this case is “not much”. The original and reconstructed rates lie almost exactly on top of one another.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# data re-built using just first two principal components y.two.pc <- y.pca$x[,1:2] %*% t(y.pca$rotation[,1:2]) # scale the re-built series to have same mean and stdev as original series y y.two.pc <- t(apply(y.two.pc,1,function(x) x * y.pca$scale + y.pca$center)) # transform into a zoo series y.two.pc <- zoo(y.two.pc,time(y)) # plot reconstructed vs. original series - they are almost indistinguishable # this shows the first two principal components capture almost all the information in y df <- rbind(fortify(y,melt=TRUE),fortify(y.two.pc,melt=TRUE)) df[,"Rate"] <- c(rep("Actual",nrow(df)/2),rep("Reconstructed",nrow(df)/2)) ggplot(df) + geom_line(aes(x=Index,y=Value,colour=Rate,group=Rate)) + facet_grid(Series ~ .) + theme_bw() + ylab("Government Bond Yield %") + theme(legend.position="bottom",axis.title.x=element_blank()) |
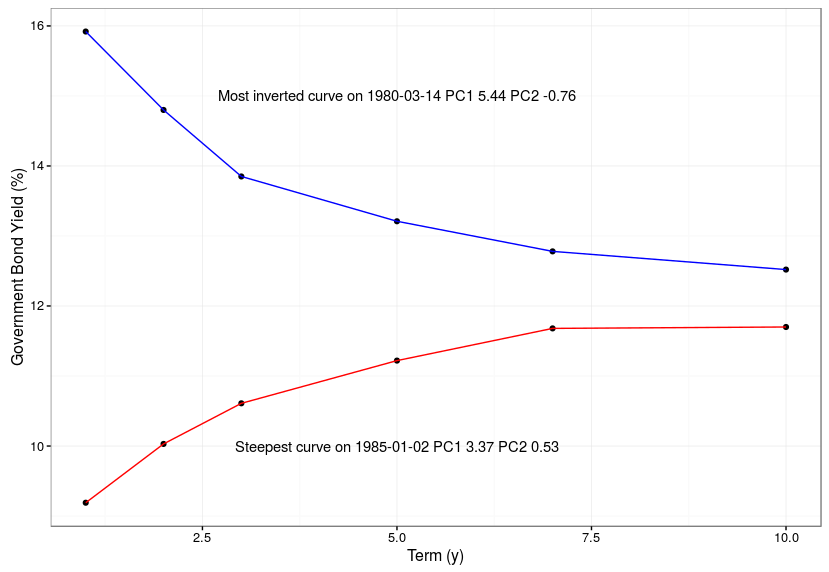
We can take a look at the curves on two days when the second principal component (steepness) was at is largest and smallest values. As you can see the curve was either inverted or strongly upward sloping on these days.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# show curves at extremes of second principal component (steepness) i.steepest <- which.max(y.pca$x[,2]) i.flattest <- which.min(y.pca$x[,2]) df.steepest.flattest <- data.frame(cbind(term=c(1,2,3,5,7,10) ,steepest=as.numeric(y[i.steepest,]) ,flattest=as.numeric(y[i.flattest,]))) steepest.label <- paste("Steepest curve on",time(y)[i.steepest] ,"PC1", round(y.pca$x[i.steepest,1],2) ,"PC2", round(y.pca$x[i.steepest,2],2)) flattest.label <- paste("Most inverted curve on",time(y)[i.flattest] ,"PC1", round(y.pca$x[i.flattest,1],2) ,"PC2", round(y.pca$x[i.flattest,2],2)) ggplot(df.steepest.flattest) + geom_point(aes(x=term,y=steepest)) + geom_line(aes(x=term,y=steepest),colour="red") + geom_point(aes(x=term,y=flattest)) + geom_line(aes(x=term,y=flattest),colour="blue") + annotate(geom="text",x=5,y=10,label=steepest.label) + annotate(geom="text",x=5,y=15,label=flattest.label) + theme_bw() + xlab("Term (y)") + ylab("Government Bond Yield (%)") |